Pytorch框架学习—图片分类
导入必要的库和模块
1
2
3
4
| import torch
from torchvision import models, transforms
from torchvision.models import ResNet101_Weights
from PIL import Image
|
加载与训练的ResNet101模型
1
2
3
|
resnet = models.resnet101(weights=ResNet101_Weights.IMAGENET1K_V1)
|
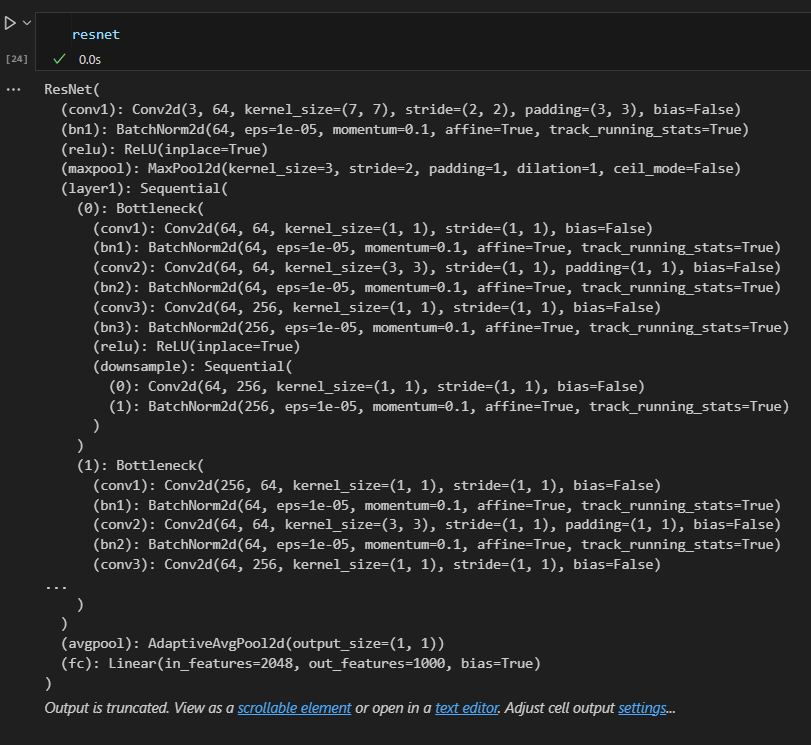
深度残差网络(ResNet-101)使用“残差块”,通过引入快捷连接解决深层网络中的梯度消失问题。ResNet-101有超过百万个参数,适合处理复杂的图像特征。
图像预处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
|
深度学习模型对于输入的尺度比较敏感,因此通常需要对输入的数据进行标准化处理。这样可以保证输入分布与训练数据一致,从而提高模型的泛化能力。
加载和预处理图像
1
2
3
4
5
6
|
img = Image.open("./Resnet/Image/image1.jpg")
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
|
卷积神经网络的期待输入的图片张量形状为(batch_szie,channels,height,weight),在这里,unsqueeze在第0维度增加了batch大小。
设置模型的模式
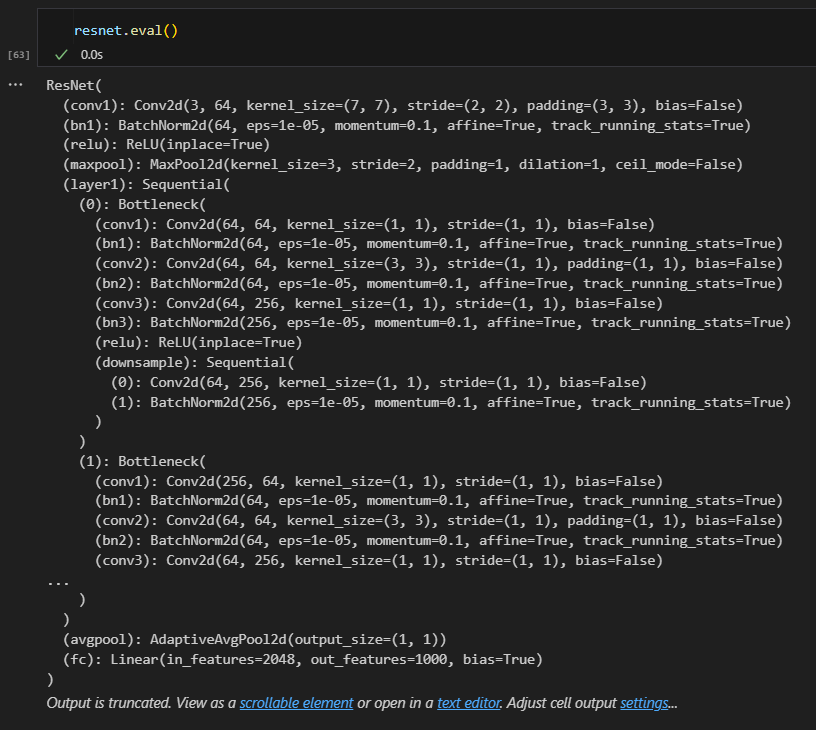
在训练和评估时,某些层(如 dropout 和 batch normalization)会有不同的行为,eval() 方法确保它们在预测阶段保持一致。
获取模型输出并计算预测类别
1
2
3
4
|
out = resnet(batch_t)
_, index = torch.max(out, 1)
|
ResNet 输出的是一个长度为1000的张量,每个值对应一个类别的“未归一化”概率。torch.max 用于提取模型认为最可能的类别。
使用Softmax获得类别的百分比
1
2
3
|
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
|
Softmax 层将向量值转化为概率分布,用于多分类问题的输出,确保总概率为100%。
获取ImageNet标签并打印模型预测的标签和百分比
1
2
3
4
5
6
|
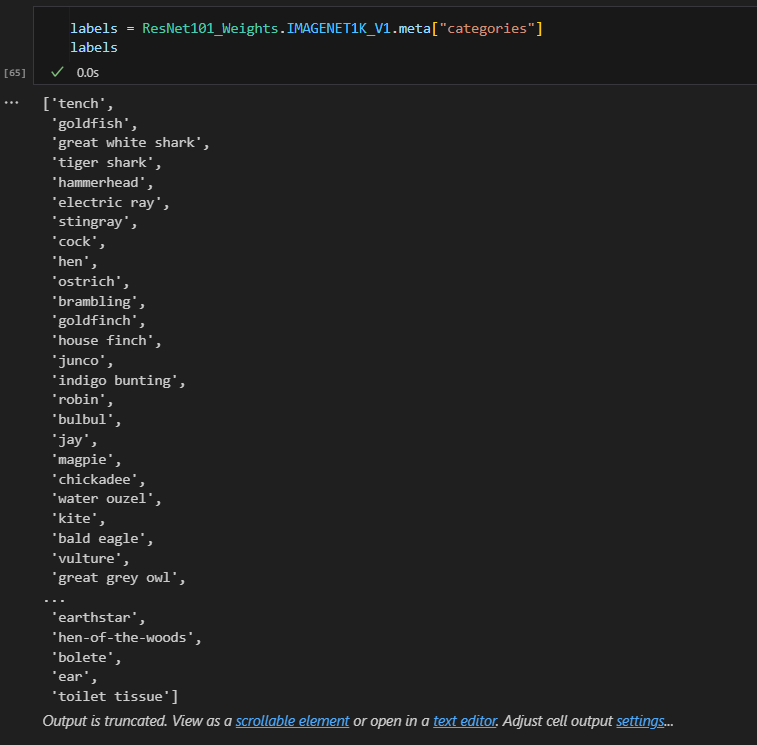
labels = ResNet101_Weights.IMAGENET1K_V1.meta["categories"]
predicted_label = labels[index[0]]
print(f"Predicted label: {predicted_label}, Confidence: {percentage[index[0]].item():.2f}%")
|
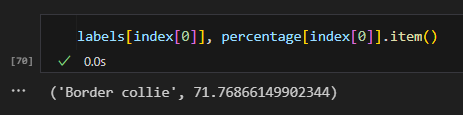
ResNet101_Weights.IMAGENET1K_V1 中的 meta 提供类别标签字典,模型输出的类别索引对应到实际的标签名称。
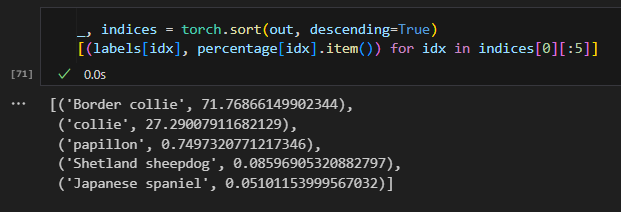
概率分布前五的label
完整代码实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| import torch
from torchvision import models, transforms
from torchvision.models import ResNet101_Weights
from PIL import Image
resnet = models.resnet101(weights=ResNet101_Weights.IMAGENET1K_V1)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
img = Image.open("./Resnet/Image/image10.jpg")
img_t = preprocess(img)
batch_t = torch.unsqueeze(img_t, 0)
resnet.eval()
out = resnet(batch_t)
_, index = torch.max(out, 1)
percentage = torch.nn.functional.softmax(out, dim=1)[0] * 100
labels = ResNet101_Weights.IMAGENET1K_V1.meta["categories"]
predicted_label = labels[index[0]]
print(f"Predicted label: {predicted_label}, Confidence: {percentage[index[0]].item():.2f}%")
|
Jupyter脚本文件下载